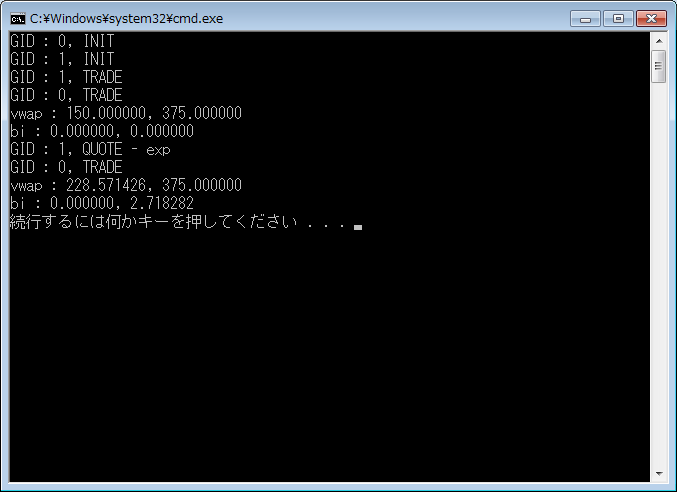
とうとうOpenCLでVWAP計算が動作した。
しかしながら、まだシングルスレッドで一周のみの動作しかさせていないので、
複数スレッドで連続計算できるように改修が必要だ。
カーネル関数自体の動作は確認できたので、作業はだいぶ楽になった。
OpenCLのDebugではFermi以降のCUDAと同様kernel関数内部でのprintfが使える。
書式はC/C++と同様で、文字列なども難なく扱える。
表示が実際に行われるタイミングは非同期のようだが、同期を行えば確実に表示できる。
clWaitForEvents関数がそれで、第一引数に待ちイベント数、第二引数にイベント配列を渡す。
イベント配列はカーネル関数実行時やメモリ読み書き時に指定できるので、
カーネル関数実行時に設定したイベントをこの関数に渡してやればよい。
・OpenCL 1.1のKhronos公式のリファレンス
知りたい関数などを一発で検索できるため大変便利
http://www.khronos.org/registry/cl/sdk/1.1/docs/man/xhtml/